线上使用pprof实践
初始化pprof
首先在main函数里,导入pprof的包,定义下端口等信息。
1 | go func() { |
1. 导入pprof路由
首先在main函数里,导入pprof的包,定义下端口等信息。匿名导入:_ "net/http/pprof" 一般是最常用和快捷的方式。它的 init() 函数会把 pprof 相关的路由(如 /debug/pprof/, /debug/pprof/heap 等)自动注册到 http.DefaultServeMux 这个默认的 HTTP Muxer 上。
2. 进入pod,执行命令抓取pprof文件
这里一般就是exec直接进
1 | kubectl exec -it <your-pod-name> -n <your-namespace> -- /bin/bash |
拿到cpu(因为是线上环境,只取30s),内存,和goroutine的信息。
1 | wget -O cpu.pprof http://localhost:6060/debug/pprof/profile?seconds=30 |
3. 拷贝文件到本地
从pod里用kubectl cp命令拷到机器,之后可以用lrzsz等命令搞到本地
1 | kubectl cp qapm-tencent/profile-analyzer-56c8475fb-tff7p:/data/service/profile/tmp_profile/cpu.pprof ./cpu.pprof |
4. pprof分析用命令行做排查
使用命令行的方式(不是太建议,除非问题很好排查):
1 | # 1. 使用Go程序生成的CPU profile文件启动pprof交互式命令行 |
5. pprof分析用页面做排查
这里重点介绍下如何用pprof提供的页面来做排查,这也是比较推荐的排查方式,相比命令行更为直观
1 | go tool pprof -http=:8080 heap.out |
此命令会自动在浏览器中打开 http://localhost:8081 ,之后就可以直接看到pprof的页面了,没有自动跳转就浏览器敲下。
解读关键视图和指标
在 Web UI 的 “VIEW” 菜单中,有几个主要使用的视图这里来介绍一下:
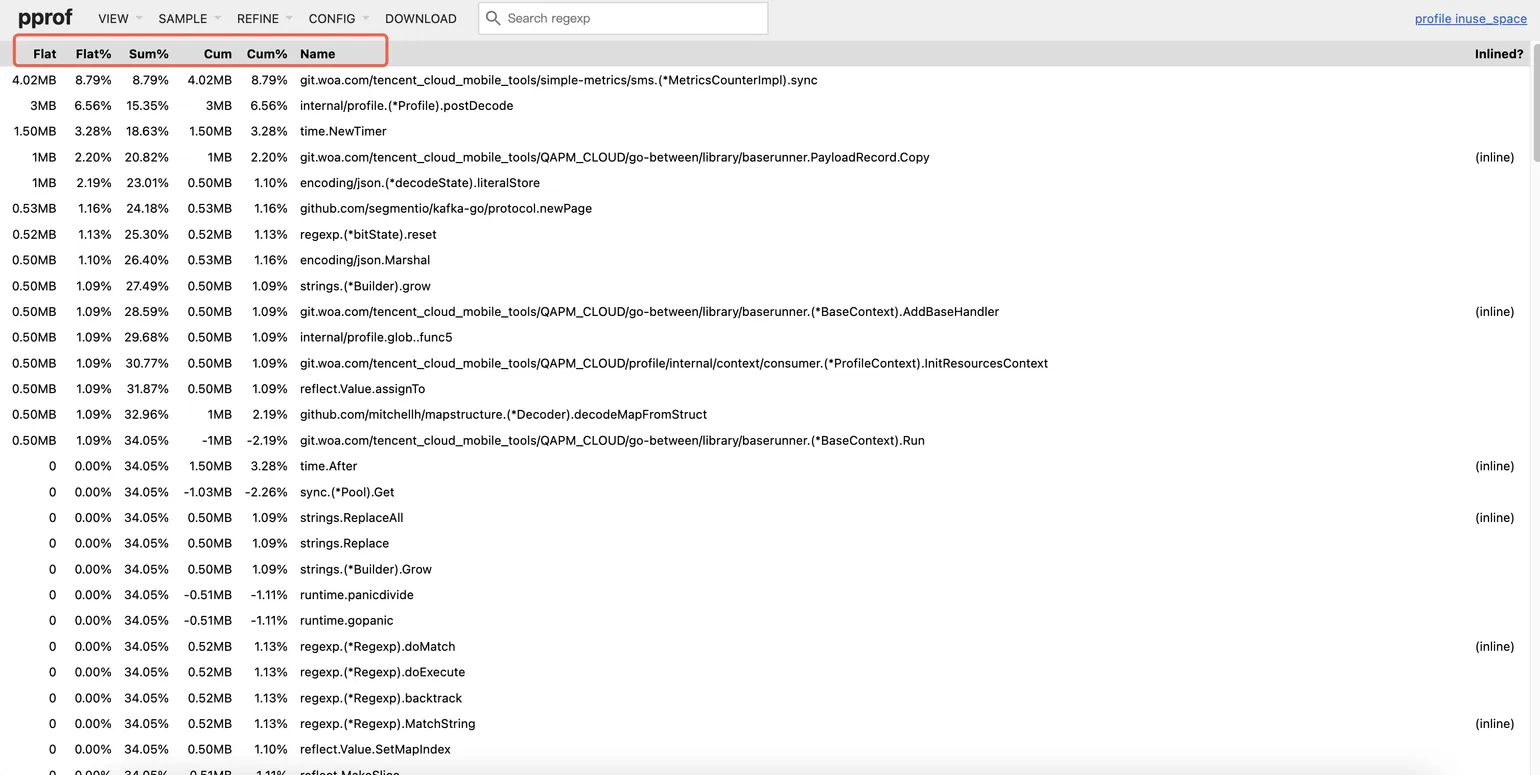
Top 视图
flat:直接内存,表示函数自身代码直接分配的内存。如果某个函数的 flat 值很高,说明该函数内部存在大量内存分配逻辑(如频繁创建对象、大数组等)。
cum (Cumulative):累计内存,包含函数自身及其所有调用链下游函数的内存总和。cum 值高的函数通常是内存问题的入口点,指引你从调用链顶端开始排查。
排查思路:优先关注 cum 值高的函数,找到关键调用路径,之后在路径中筛选 flat 值也高的函数,定位具体分配点
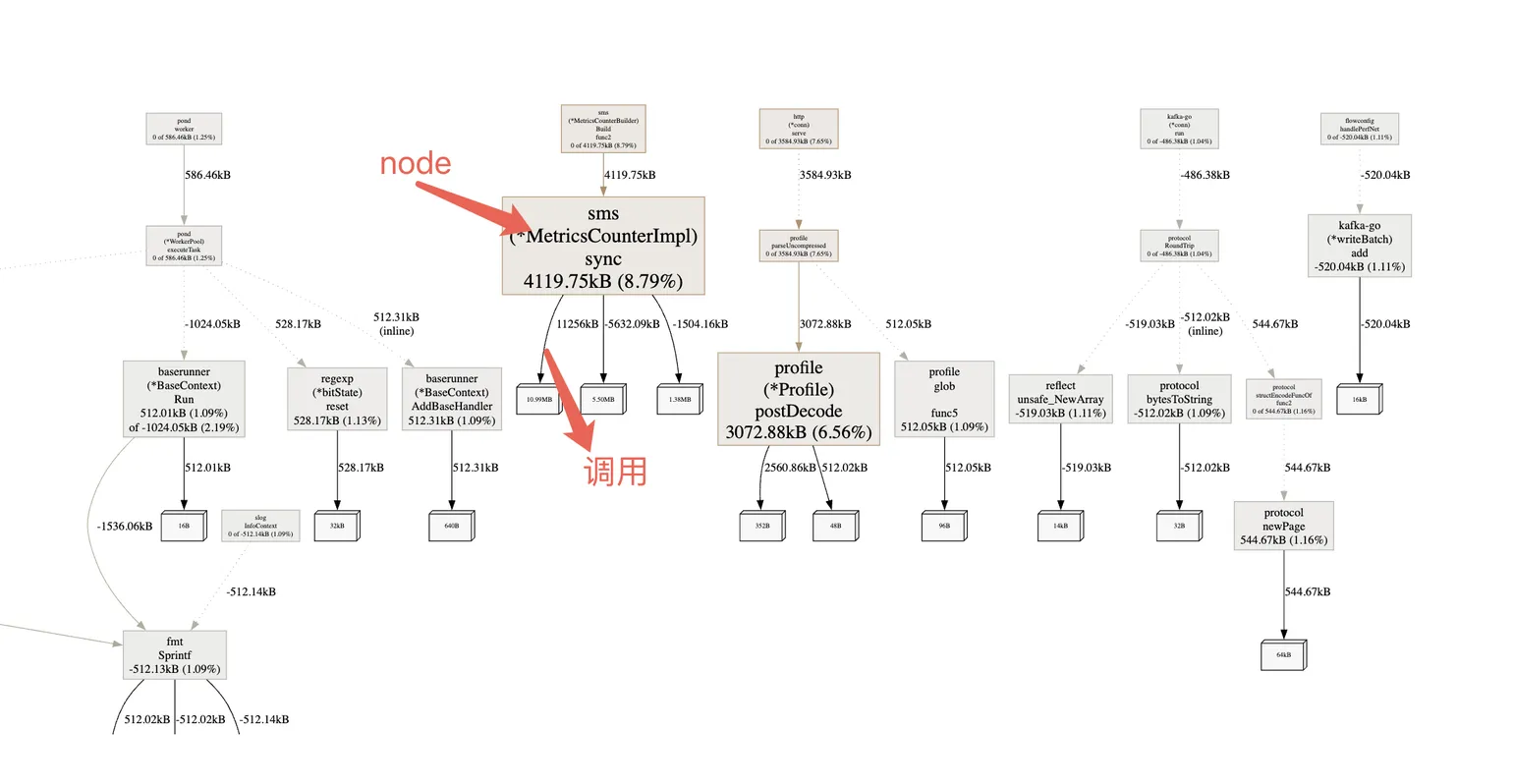
Graph (调用图) 视图
通过节点和连线直观展示函数间的内存流转:
- 节点大小:反映函数的累计内存(cum)占比,越大表示消耗越多
- 连线粗细:表示调用关系中的内存传递量,越粗说明下游分配越多
排查思路:在图中找红的大的节点,它们通常是问题的核心,结合代码逻辑来看是否合理。
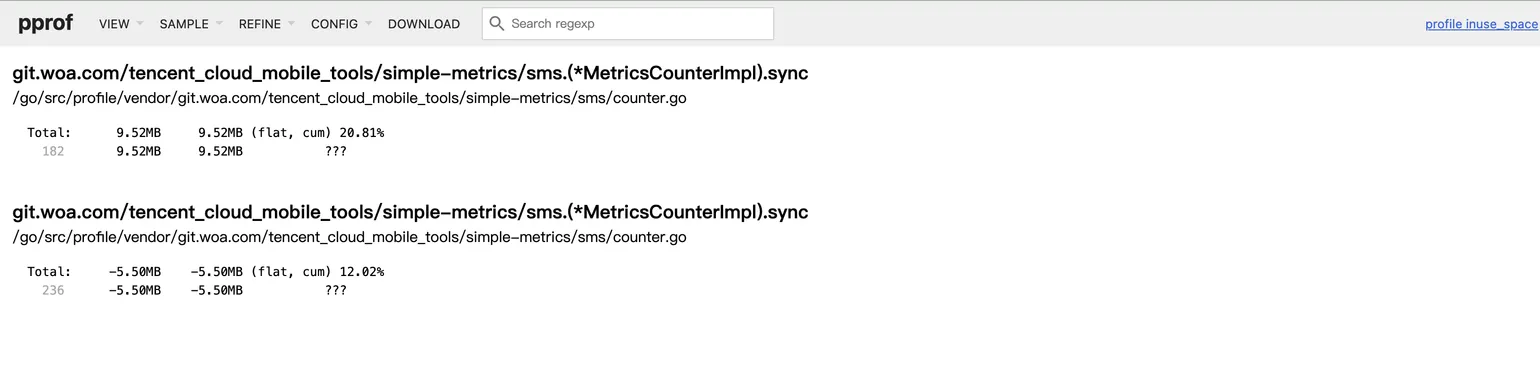
Source (源码) 视图
当从 Graph 视图点击函数节点后,会跳转到源码级分析。
这里会直接展示该函数的源代码,并在每一行代码的左侧标注出该行分配的内存大小。
排查思路:这里一般是看具体代码,通常是排查的最后一步。在这里,你可以看到到底是什么函数导致了内存分配,不过在前面几张视图排查之后,基本也可以将内存泄漏锁定到函数级别。
内存泄漏深度排查
如果说用上述这些方式还是无法排查出来,就需要用对比分析来找出内存泄漏了。
内存分析的核心:理解 heap 和 allocs
pprof 提供了多种内存信息,相对来说,对于排查内存泄漏,我们最关心的是 heap;对于排查 GC 压力,allocs 更为重要。
heap(堆内存):这是当前时刻,程序运行时还存活在堆上的对象信息。这是排查内存泄漏的首选。它展示了哪些对象占用了内存,并且一直没有被释放。
allocs(累积分配):自程序启动以来,所有在堆上发生过的内存分配,即使它们已经被释放。这个剖面适合用来分析内存抖动或GC压力问题,找到那些频繁进行小对象分配和释放的”坏代码”。
对于缓慢的内存泄漏,单次抓取很多时候看不出问题,因为所有函数都在正常分配内存。对比分析就显得比较重要。
对比分析操作步骤
在服务刚启动、内存正常时,采集一次pprof内存信息:
1 | wget -O heap_base.pprof http://localhost:6060/debug/pprof/heap |
让服务运行一段时间(例如几小时或一天),在内存明显增长后,再次采集。如果内存泄漏场景比较复杂的话,这里其实可以写个定时采集脚本一直采。下面是排查一个长期泄漏的一个抓取脚本示例:
1 |
|
然后在后台运行:
1 | nohup ./capture_pprof.sh >> capture_pprof.log 2>&1 & |
在本地启动 pprof 进行对比
1 | go tool pprof -http=:8081 -base heap_base.out heap_leaked.out |
分析对比结果
-base参数以你给 pprof 的第一个文件作为基准,从上面的例子看就是heap_base.out。现在,pprof 的所有视图(Top, Graph)展示的将是内存的增量,也就是
heap_leaked.out相比heap_base.out增长了多少。那些正常的、有分配有回收的函数,其内存增量会很小或为零,甚至是负数。
而造成泄漏的函数,因为其分配的内存只增不减,会在对比视图中颜色会比较深。下图没有明显泄露,所以最多是黄色,泄漏很多的一般会是红色。
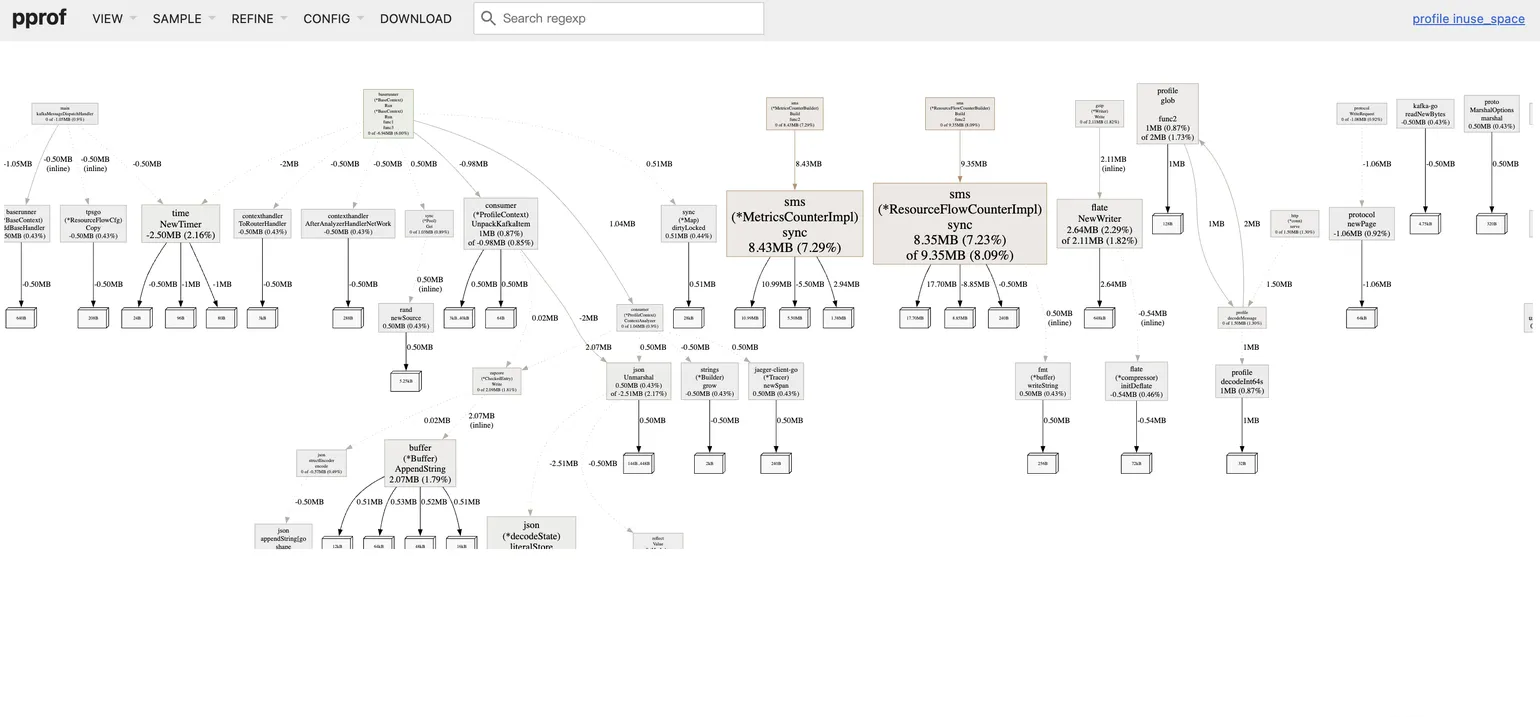
Goroutine 泄漏
有时内存增长的根因并非对象泄漏,而是 Goroutine 泄漏。每个 Goroutine 都会消耗至少 2KB 的栈内存,如果大量 Goroutine 被创建后无法退出,累积起来的内存消耗也会非常多。
使用 goroutine.pprof 的分析方法与 heap.pprof 完全相同。在 Graph 视图中,你需要寻找的是那些启动了 Goroutine 却因为某种原因(如 channel 阻塞、死循环)导致其无法退出的调用链。
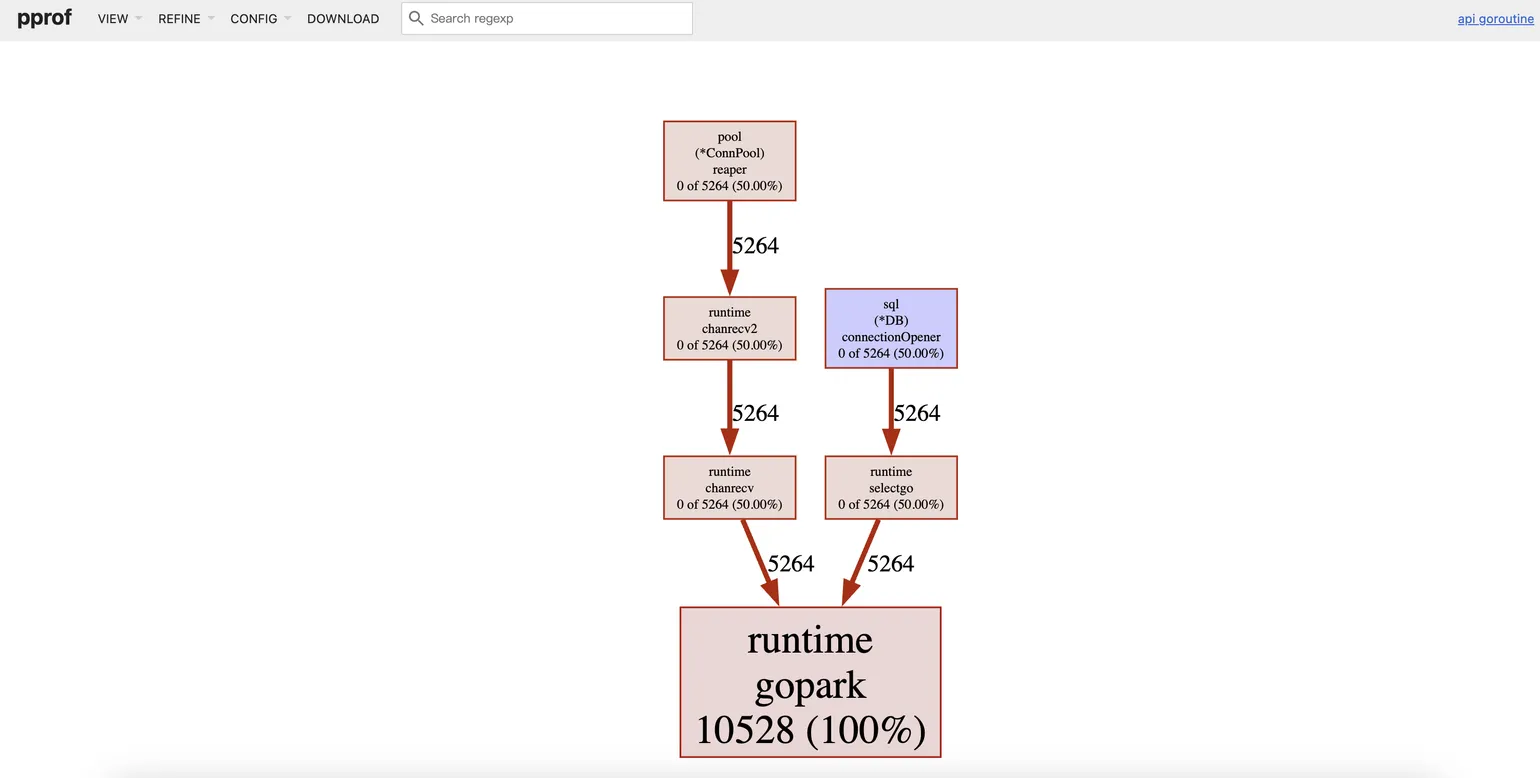
下图是一个明显goroutine泄漏的pprof对比图,可以很好的锁定是数据库相关的函数导致的泄漏。
1 | go tool pprof -http=:8081 -base billing-goroutine02171730.out billing-goroutine03031030.out |
小结
pprof 是一个功能极其强大的工具,但工具本身并不能一下子解决问题,核心在于我们的分析思路。
核心要点
明确目标:明确是去排查什么问题,是内存骤增还是缓慢泄漏。
善用可视化:相比于命令行,Web UI 的 Graph 和 Source 视图能将问题从数据层面直观地映射到代码层面,极大提升效率。
对比和定期抓取是个很好的方法:对于难以发现的缓慢泄漏,pprof 的对比分析能力是最终的解决方案。
养成习惯:将 pprof 端点作为所有服务的标配,将性能分析融入日常开发和测试流程。
建立一套基于pprof的行之有效的性能问题排查流程对于一个golang开发者来说是非常重要的。希望这篇文章能为你将来面对类似问题时,提供一份清晰的行动指南。

