文章主要是对ClickHouse - Lightning Fast Analytics for Everyone这篇2024在VLDB会议最新发布的论文做个精读,这篇论文详细介绍了ClickHouse,这个让我们熟知的为大规模数据集的高性能分析设计的列式OLAP数据库。面对数据量的爆炸式增长所做的架构设计和优化处理,ClickHouse通过高效的数据存储和实时分析能力,解决了企业在处理海量数据时遇到的挑战。
引言
ClickHouse 于 2009 年启动,并于 2016 年开源。下图展示了ClickHouse的功能历史。

ClickHouse 旨在应对以下五个挑战:
- 在海量数据集下保持高摄取率
- 在多个并发查询情况下保证低延迟
- 多样化的数据存储系统、存储位置和格式
- 拥有支持性能自省的便捷查询语言
- 拥有工业级的健壮性和多样化的部署方案
架构设计
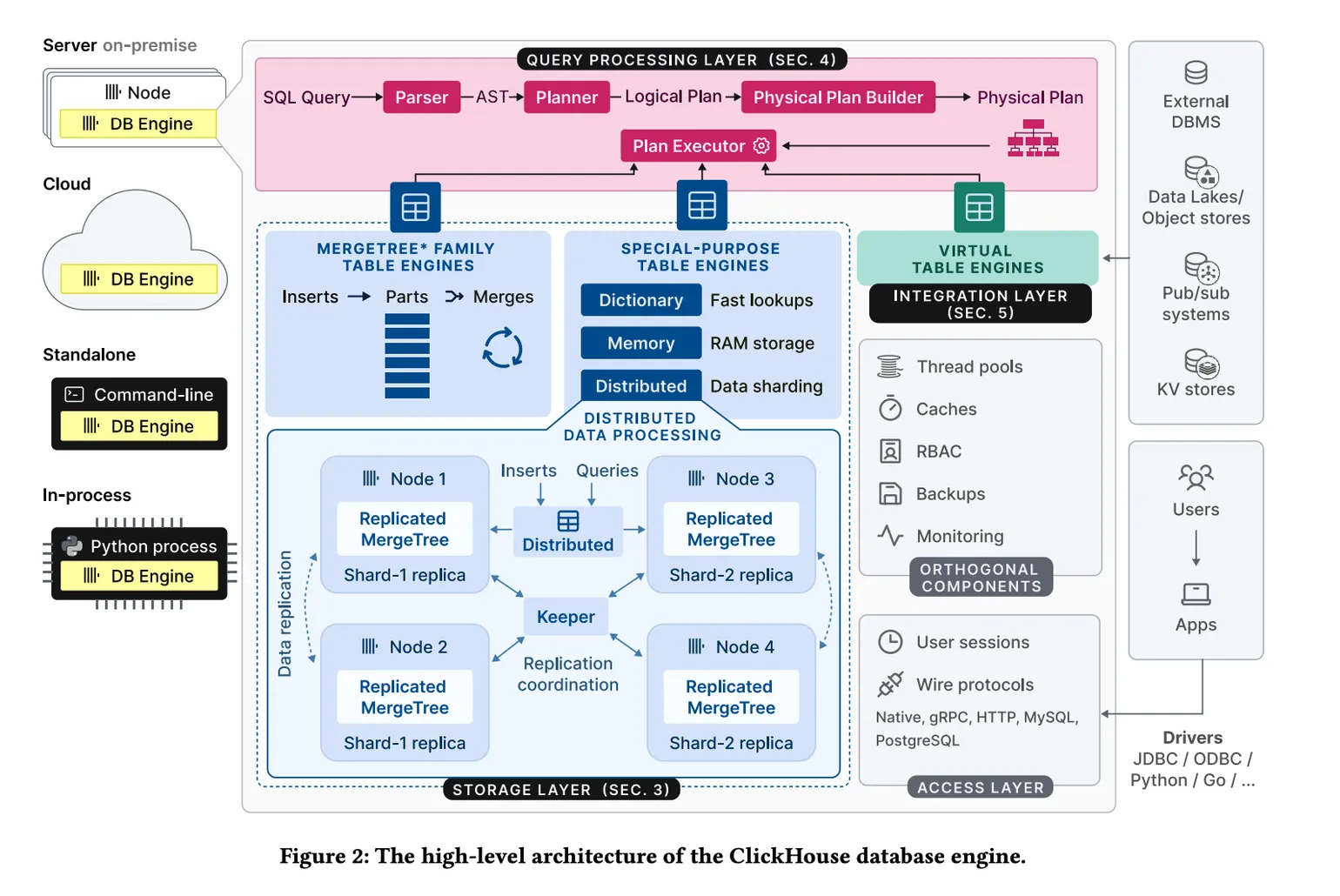
首先来看下架构部分,上图展示了ClickHouse数据库引擎的高层架构,分为以下几个主要部分:
查询处理层(SEC.4):负责解析、优化和执行SQL查询。查询经过逻辑和物理查询计划的转换,并使用向量化执行模型处理数据。
存储层(SEC.3):由多种表引擎组成,主要是MergeTree*引擎,它处理数据的持久化、分片、压缩和合并。数据被存储为多个部分,并在后台进行合并操作。
集成层(SEC.5):包括与外部系统的连接和数据交换,支持多种格式和协议,如PostgreSQL、Kafka、S3等,提供对外部数据源的透明访问。
此外,还有访问层负责管理用户会话和与应用程序的通信,线程、缓存、角色访问控制、备份和监控等辅助组件。
存储层
MergeTree表引擎是ClickHouse的核心,它基于LSM树结构,专为处理海量数据设计。数据被拆分为多个不可变的”部分”(parts),并在后台定期合并,以减少碎片和优化存储。每个部分包括元数据和实际数据,按照主键排序,便于快速查找。
MergeTree核心特性
1. 数据分片与存储
水平分片(Sharding):将数据分布在多个节点上,每个分片存储部分数据,从而提高系统的扩展性和并行查询能力。分片是通过自定义的分区表达式实现的,可以按需对数据进行逻辑分区。
数据文件结构:每个分片中的数据存储为多个不可变的”部分”(parts),每个部分包含一组已排序的行和相应的元数据。这些部分以文件夹形式存储在磁盘上,每个列对应一个文件。
2. 合并(Merge)策略
MergeTree引擎通过后台合并作业定期将多个较小的部分合并为一个较大的部分。这种合并策略能够减少存储碎片并提高读取效率。
合并不仅可以简单地合并行,还支持多种数据转换,例如基于主键的替换合并(保留最新版本的数据行),以及聚合合并(对具有相同主键的行进行聚合计算)。
3. 数据压缩
每个部分的列数据都被压缩存储,以减少磁盘占用和I/O成本。默认使用LZ4压缩算法,此外用户可以选择其他更适合特定数据类型的压缩算法(如Gorilla或FPC)。
通过列式存储和压缩,MergeTree能够有效地减少I/O操作,特别是在处理大规模数据查询时。
4. 索引与剪枝
主键索引:MergeTree使用主键索引实现高效的数据过滤。主键索引是稀疏的,仅保存部分行的主键值和相应的偏移量,这样可以快速定位查询所需的数据块。
跳跃索引:用于快速跳过不相关的数据部分,进一步减少需要扫描的数据量。
5. 数据更新与删除
- MergeTree的设计偏向于追加写入(append-only)模式,但也支持数据更新与删除操作。更新操作可以通过合并策略中的替换合并来实现,删除操作则通过轻量级删除标记来处理,实际的物理删除会在后续合并过程中进行。
6. 容错与高可用性
- 数据复制(Replication):通过ReplicatedMergeTree引擎,ClickHouse支持数据的多副本存储,以确保系统在单点故障时仍能保持高可用性。复制机制使用Raft一致性算法,保证数据在多个副本之间的一致性。
7. 数据分区与TTL
分区:用户可以定义分区键,按时间或其他维度对数据进行分区,从而优化查询性能和存储管理。
TTL(Time-to-Live):支持基于TTL的自动数据老化和删除策略,用户可以设置数据的生存时间,超过时间的数据将自动移动到慢速存储或被删除。
8. 同步异步插入区别
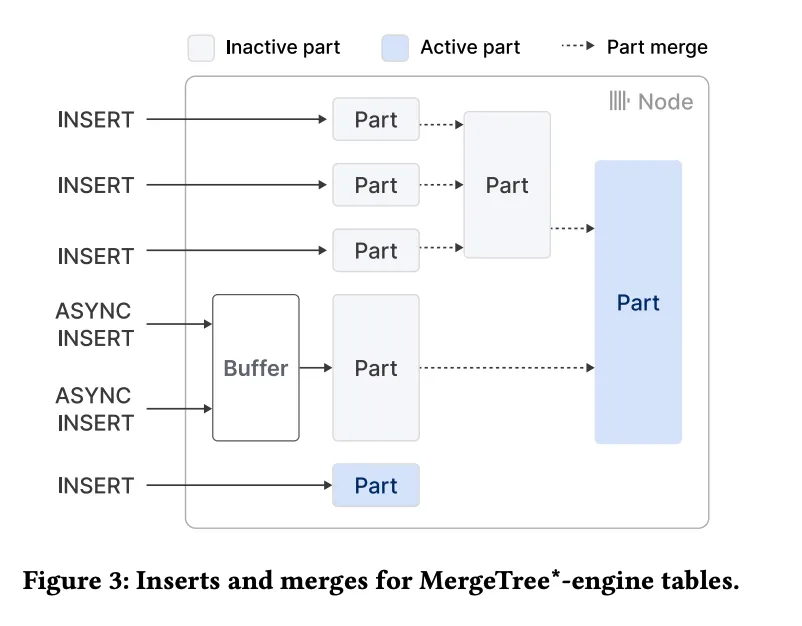
上图展示了数据插入到MergeTree表引擎后的处理流程,重点说明了同步插入和异步插入的不同模式及其影响:
同步插入:每次插入语句都会创建一个新部分,并附加到表中。这种模式下,客户端通常会将数据批量插入,以减少合并开销。
异步插入:在这种模式下,ClickHouse会将多个插入请求的数据缓冲在同一张表中,只有当缓冲区达到一定大小或超时后,才会生成一个新部分。这种方式更适合实时数据场景,如监控系统的数据上报。
总结
总的来说,MergeTree表引擎是ClickHouse高性能的基础,结合了高效的数据存储、智能的合并策略、强大的压缩和索引功能,使得ClickHouse在处理大规模、复杂的实时查询时表现出色。
索引策略
主键索引:主键列决定了行在部分内的排序,并生成稀疏索引,大幅减少查询时扫描的数据量。
跳跃索引:通过存储小粒度的元数据块,跳跃索引进一步减少不必要的数据扫描。
ClickHouse支持多种数据分片和复制策略,通过分片(Sharding)和复制(Replication)提升系统的可扩展性和高可用性。数据分片通过分区表达式对数据进行水平拆分,分布在不同的节点上;复制则保证每个分片有多个备份,以防单点故障。
查询处理层
ClickHouse的查询处理层是其核心组件之一,负责解析、优化和执行SQL查询,确保高效的数据处理。查询处理层的设计使其能够在多核、多节点环境下并行处理大规模数据查询,主要包括以下几个关键部分:
1. 向量化执行模型
ClickHouse采用向量化执行模型(vectorized execution model),每次处理一组数据行(称为数据块),而非逐行处理。向量化模型能有效减少函数调用和内存访问的开销,充分利用现代CPU的SIMD(单指令多数据)指令,从而提高执行效率。
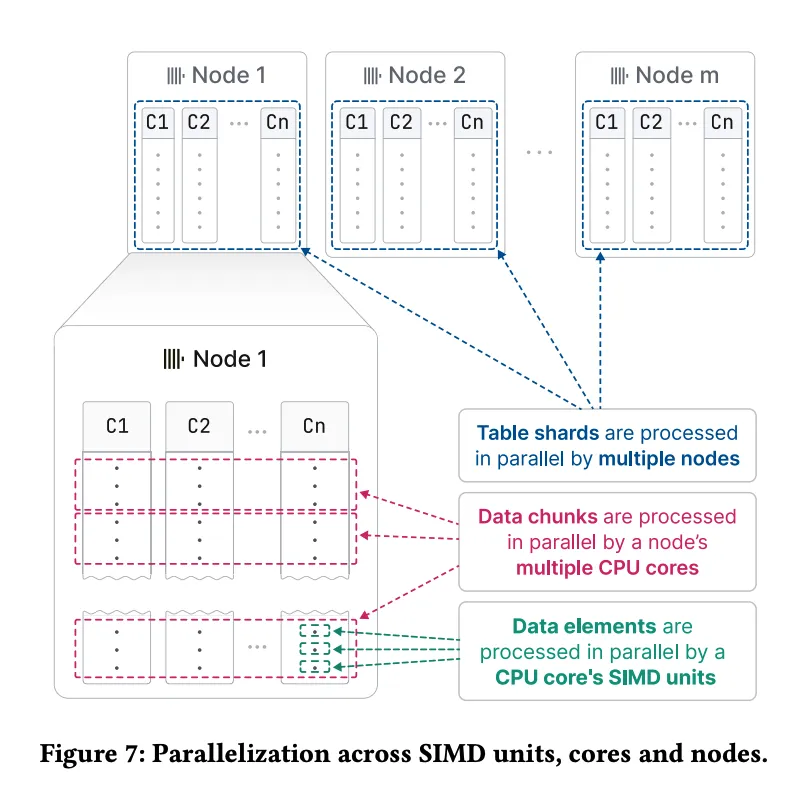
- SIMD并行化:上图展示了SIMD并行,多核并行及多节点并行的处理机制,其中ClickHouse通过SIMD指令集并行处理多个数据元素,使得单个CPU时钟周期内能够处理多行数据。这种并行化技术能够显著提高查询处理的速度,尤其是在处理大规模数据集时。
2. 查询优化
查询优化过程分为多个阶段,逐步将SQL查询转化为可执行的物理操作计划:
语义查询优化:首先对查询的抽象语法树(AST)进行优化,如常量折叠、子表达式消除和谓词下推等。
逻辑查询计划优化:优化后的AST被转换为逻辑查询计划。在这个阶段,系统会根据不同操作的代价对顺序进行调整,比如将过滤操作尽量前置,以减少不必要的数据扫描。
物理查询计划优化:逻辑计划最终转换为物理计划,该计划考虑了具体的存储引擎特点。例如,如果表的主键列与查询的排序列匹配,ClickHouse可以利用排序跳过不必要的数据。
3. 并行执行
查询执行层在多个层级实现并行化,除了之前提到的SIMD并行,还有多核及多节点并行,最大化利用硬件资源:
- 多核并行:ClickHouse能够将查询拆分成多个执行线程,每个线程处理一部分数据。在单个节点上,多线程的并行执行加速了查询处理。
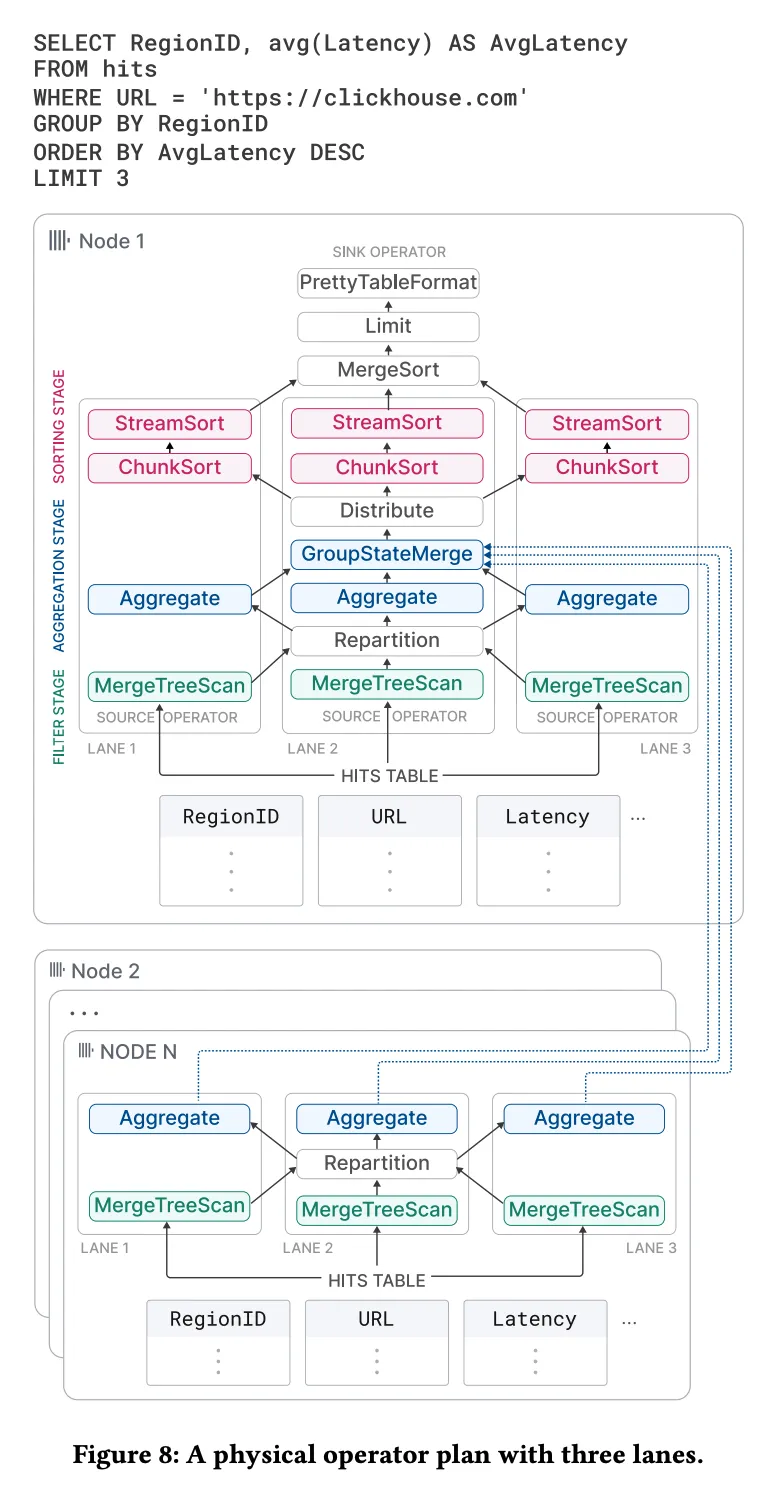
- 多节点并行:如果表被分片存储在多个节点上,查询处理器可以将查询分布到不同节点上并行执行。节点之间的结果通过网络汇总到发起查询的节点,完成最终的结果计算。上图显示了在保存命中表分片的其他节点上执行的计划片段。这些节点对本地数据进行过滤和分组,并将结果发送到发起者节点也就是Node1。Node 1 上的 GroupStateMerge 运算符将本地和远程的结果合并,然后对结果组进行最终排序。
4. 即时编译(Just-in-Time Compilation, JIT)
ClickHouse支持基于LLVM的即时编译,将多个相邻的查询操作合并为一个操作,从而减少了虚函数调用和内存访问次数。JIT编译能够在查询过程中动态生成高度优化的代码,尤其是在重复查询模式下,能显著提升执行性能。
- 代码合成:JIT编译不仅能合成简单的表达式,还可以合成复杂的聚合和排序操作,从而减少上下文切换,提高CPU缓存命中率。
5. 资源管理与隔离
ClickHouse的查询处理层还提供了强大的资源管理功能,确保在高并发环境下,各类查询任务能够合理分配系统资源:
并发线程控制:ClickHouse动态调整查询线程数,以避免线程过载,同时最大化利用可用CPU核心。
内存使用限制:系统为查询分配内存时,可以设置内存限制。超过内存限制的查询可以自动切换到外部算法,以避免内存溢出。
I/O调度:ClickHouse允许用户对不同类型的查询任务设置I/O带宽限制,确保关键任务不会因I/O瓶颈受到影响。
6. 动态执行与调整
在查询执行过程中,ClickHouse的操作符可以根据实时情况动态调整,例如当内存使用超限时,操作符可以切换到外部聚合或排序算法。这种动态调整机制提高了查询的鲁棒性,确保即使在复杂的查询环境下,系统也能维持稳定的性能。
ClickHouse的查询处理层通过向量化执行、并行化处理、即时编译和动态优化,能够在多核多节点环境中高效执行大规模数据查询,适应现代数据密集型应用的需求。
数据整合层
数据整合层是ClickHouse与外部数据系统和存储服务交互的桥梁,旨在实现多源数据的统一分析和处理。它为ClickHouse提供了丰富的集成功能,使其能够与各种外部数据源无缝对接,包括传统关系数据库、消息队列系统、云存储和数据湖等。
1. 集成表函数(Integration Table Functions)
集成表函数是一种轻量级的方式,允许用户在SQL查询的FROM子句中临时引入外部数据。通过集成表函数,ClickHouse可以在不改变原有数据架构的情况下,快速读取外部数据源的数据,用于临时查询和探索性分析。
读取外部数据:用户可以在查询中调用表函数来读取外部系统的数据,这种方式特别适合对外部数据的临时访问,避免了复杂的数据导入操作。
写入外部数据:集成表函数同样支持将查询结果写入外部系统,满足了与第三方系统的数据交换需求。
2. 持久化的外部表访问
持久化表引擎提供了对外部数据源的长期访问方式,用户可以将外部表定义为ClickHouse中的持久化表,从而实现对外部数据的持续访问和管理。
表引擎(Table Engines):表引擎是ClickHouse访问外部数据的主要方式。用户可以通过
CREATE TABLE语句将外部数据源表定义为ClickHouse的本地表,从而实现透明的外部数据访问。表引擎可以被动地将查询转发到外部系统,也可以主动定期拉取数据或订阅外部系统的变化。被动表引擎:执行查询时,将查询转发到外部数据源,并将结果缓存到本地代理表中。
主动表引擎:定期从外部系统拉取数据,或者通过像PostgreSQL的逻辑复制协议这样的机制订阅数据变更,将数据同步到本地表中。
数据库引擎(Database Engines):不仅限于单个表,数据库引擎能够将整个外部数据库的模式映射到ClickHouse中。这种映射使得外部数据库的所有表都能够被ClickHouse查询,并且支持一定程度上的DDL操作,如创建或删除表。
- 虚拟表引擎:通过虚拟表引擎,ClickHouse还可以与非关系型的数据存储交互,如Kafka、Redis和MongoDB等,实现双向数据交换和实时处理。
字典(Dictionaries):字典是一种特殊的表引擎,能够从几乎所有可能的数据源中提取数据。这些数据源可以通过表函数或表引擎来访问,字典会定期从外部存储中拉取数据并更新。
3. 数据格式支持
ClickHouse支持多达90种以上的数据格式,使其能够与多种外部系统进行交互。这些格式包括传统的CSV、JSON、Parquet、Avro,以及适用于大数据分析的专用格式。
输入格式:ClickHouse可以读取的数据格式。这些格式通常用于从外部系统导入数据。
输出格式:ClickHouse可以导出的数据格式。这些格式通常用于将处理后的数据传输到其他系统。
4. 兼容性接口
为了与现有的系统无缝集成,ClickHouse提供了与MySQL和PostgreSQL等传统关系数据库兼容的接口。这种兼容性接口特别有助于那些现有的业务系统能够快速迁移到ClickHouse上。
- 协议兼容性:通过模拟MySQL和PostgreSQL的二进制协议,ClickHouse可以让许多现有的BI工具和应用程序与其兼容,从而减少了因数据平台迁移带来的调整成本。
ClickHouse的数据整合层通过多样化的集成方法、丰富的数据格式支持和高效的外部数据访问能力,显著扩展了其在不同应用场景中的使用范围。无论是对实时流数据的处理,还是对历史数据的分析,ClickHouse都能够通过数据整合层实现与外部系统的高效交互。
核心功能
这部分是ClickHouse如何具有的高效的数据处理和管理功能,怎么能够在大规模、高并发场景下实现出色的性能的原因。以下是其核心功能的详细介绍:
1. 高效的数据插入与更新
ClickHouse的设计初衷就是处理海量数据的高速插入与查询。所以插入和删除也是按照这个思考来的。
无重复插入(Idempotent Inserts):ClickHouse允许数据在出现网络超时等情况下进行重复插入,而不会产生重复数据。这是通过维护一个哈希表,存储最近插入的部分的哈希值来实现的。如果新的插入操作的哈希值与已有记录匹配,则该插入操作会被忽略,从而避免数据冗余。
轻量级删除(Lightweight Deletes):ClickHouse支持两种删除方式:
- 轻量级删除:这是较快速的删除方式,只需更新一个内部位图,标记哪些行被删除,而不是物理删除数据。被标记为删除的行在查询时会被过滤掉,而物理删除操作则会在后续的合并过程中进行。
- 变更(Mutations):当需要修改或删除数据时,ClickHouse会在后台异步执行这些操作,以避免阻塞并发的插入操作。变更操作会导致相关部分的重写,并确保所有数据在操作完成后被正确更新。
TTL策略:TTL(Time-to-Live)合并策略允许用户为数据设置生存时间,超过指定时间的数据可以自动被移动到低成本的存储中,或根据策略进行聚合或删除。这对于处理时间敏感的数据(如日志数据)非常有用,能够减少存储成本并优化查询性能。
2. 数据复制与一致性
ClickHouse的高可用性和容错能力通过数据复制功能实现。
多主复制(Multi-master Replication):ClickHouse通过ReplicatedMergeTree引擎实现数据复制。每个数据分片在多个节点上都有副本,使用Raft一致性算法确保各副本之间的数据一致性。这种复制机制能够在节点故障时提供高可用性,并支持跨数据中心的容灾备份。
最终一致性:在分布式环境下,ClickHouse的复制机制采用最终一致性模型,这意味着数据可能在短时间内不同步,但最终会达到一致状态。大部分操作可以异步执行,以提高系统吞吐量,但在必要时也支持同步执行,确保数据立即一致。
3. 并行查询与性能优化
ClickHouse通过各种优化技术和并行处理能力,确保在面对高并发查询时仍能保持低延迟和高吞吐量。
分布式并行执行:ClickHouse支持多节点的分布式查询执行,将查询任务分配给不同节点并行处理。每个节点可以独立处理数据分片,最终结果由发起查询的节点汇总。这种架构确保了系统的可扩展性,能够轻松处理超大规模数据集。
查询优化与即时编译:通过查询优化和即时编译(JIT),ClickHouse能够生成针对特定查询的高度优化代码,减少查询执行时间。优化过程包括过滤下推、表达式简化和排序优化等。
哈希表优化:在执行聚合和连接操作时,选择合适的哈希表类型至关重要。ClickHouse内置了多种哈希表实现,能够根据数据的特点和查询需求动态选择最佳的哈希表,从而提高查询效率。
4. 高级数据管理
ClickHouse还支持多种高级数据管理功能,以满足复杂的数据处理需求。
- 物化视图(Materialized Views):支持基于物化视图的增量更新。物化视图允许用户将复杂查询结果预计算并存储为表,从而加快查询速度。视图的数据在源表有新数据插入时自动更新,确保视图内容始终与源表同步。
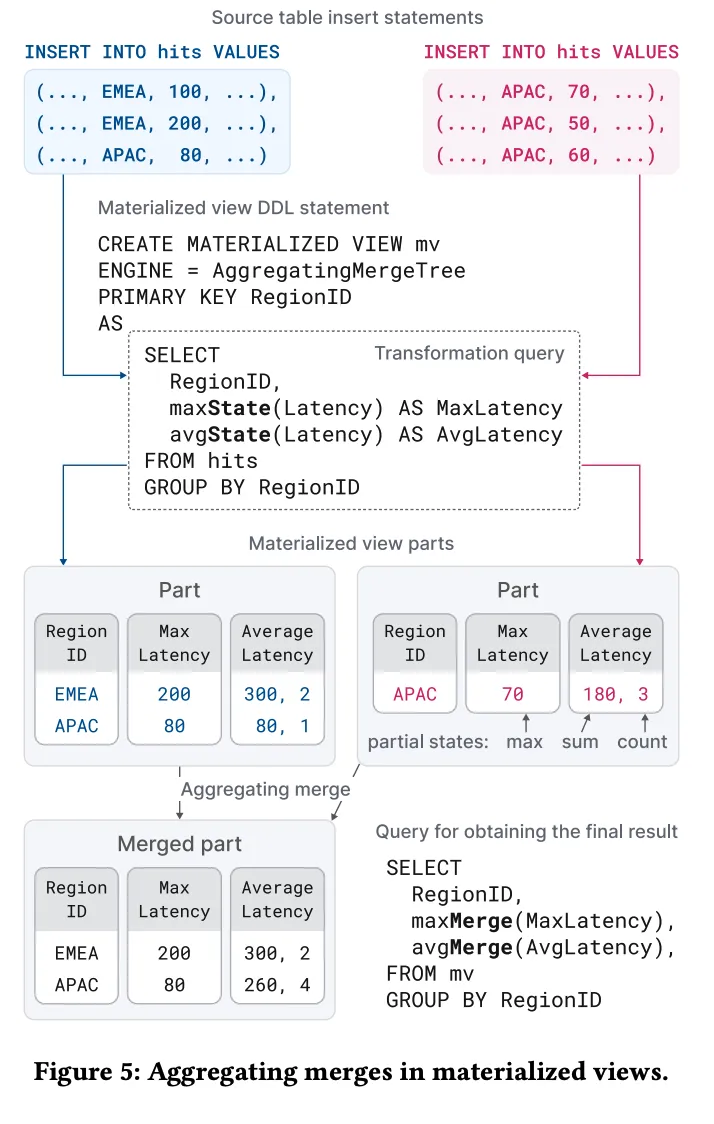
- 物化视图的创建:图中展示了一张源表(存储页面访问统计)的物化视图。该视图基于对源表的转换查询(Transformation Query)生成,该查询按地区(Region)分组,计算最大延迟(MaxLatency)和平均延迟(AvgLatency)。
- 增量更新:每当源表有新数据插入时,物化视图会自动执行转换查询,并将结果插入到视图中。这些结果以部分聚合状态(Partial Aggregation State)形式存储。
- 聚合合并:物化视图使用聚合合并策略,将具有相同主键列值的行进行合并,以生成最终的聚合结果。当用户查询视图时,系统会自动将这些部分聚合状态合并为完整的聚合结果。
- 查询视图:最终的查询可以通过对物化视图执行选择语句(SELECT)来完成。用户可以在查询中使用”FINAL”关键字来确保返回的结果是经过完整合并的最终结果。
通过这种方式,ClickHouse能够在不影响插入性能的情况下,持续更新和优化物化视图的数据,使其在处理实时和历史数据的复杂聚合查询时,既高效又灵活。
- 表投影与跳跃索引:表投影是表的另一种物理布局,通过不同的主键对数据进行重新排序,适合不同的查询模式。跳跃索引则提供了一种轻量级的数据过滤机制,可以在不使用主键索引的情况下,加快特定列的查询速度。
ClickHouse的核心功能围绕高效数据插入与更新、强大的复制与一致性、并行查询处理以及高级数据管理展开。通过这些功能,ClickHouse能够满足现代数据密集型应用对实时性、高吞吐量和大规模数据处理的需求。
查询优化与性能提升
在ClickHouse中,查询优化与性能提升是其处理大规模数据查询的关键部分。为了确保高效查询,ClickHouse采用了一系列的优化技术和方法,使得查询能够在最短时间内返回结果,尤其是在面对复杂的大数据分析任务时。以下是具体的优化和性能提升方法:
1. 查询优化技术
语义查询优化
在查询解析阶段,ClickHouse对查询语法树(AST)进行一系列的优化操作。这些优化有助于减少查询的计算负载,并为后续的物理查询计划提供基础:
常量折叠(Constant Folding):将查询中可以提前计算的表达式直接计算并替换掉,比如
2+2会被替换成4,以减少运行时的计算。公共子表达式消除(Common Subexpression Elimination, CSE):对于在查询中多次出现的相同表达式,ClickHouse会识别并只计算一次,以减少不必要的重复计算。
谓词下推(Predicate Pushdown):将过滤条件尽可能提前执行,减少数据扫描量。比如,在聚合之前执行过滤,可以显著减少需要聚合的数据行数。
IN列表优化:将多个相等条件转换为一个
IN列表,从而加速查询的执行。例如,将x=c OR x=d转换为x IN (c, d),这种转换使得查询更易于优化。
逻辑查询计划优化
在逻辑计划阶段,ClickHouse会根据查询的代价估算进一步优化查询计划:
过滤与排序顺序优化:根据估算的代价,确定过滤和排序操作的执行顺序。ClickHouse会优先执行代价较低的操作,例如在数据过滤后再执行排序,从而减少需要排序的数据量。
操作符的合并与删除:如果查询中某些操作可以合并(如多次排序合并为一次排序),或某些操作是冗余的,ClickHouse会在逻辑计划阶段进行优化,去掉不必要的操作步骤。
物理查询计划优化
物理计划是查询的最终执行计划,ClickHouse在这个阶段针对具体的存储引擎和数据特性进行优化:
主键索引利用:如果查询条件中包含主键列的过滤,ClickHouse会利用主键索引进行数据剪枝(跳过不相关的数据块),从而减少数据扫描量。
排序与聚合优化:对于排序和聚合操作,如果表的排序列与主键列匹配,ClickHouse可以利用已有的排序顺序,避免重复排序或使用高效的排序聚合方式。
2. 性能提升技术
即时编译(Just-in-Time Compilation, JIT)
ClickHouse通过LLVM实现即时编译,将复杂的查询操作转化为高度优化的机器代码,提高执行效率:
操作符融合:将多个查询操作融合为单个操作符,减少函数调用和数据传输的开销。例如,将
a * b + c转化为一个连续的操作符,而不是分开计算。表达式编译:在查询中,对表达式进行编译,使得常用的表达式可以直接作为本地代码执行,避免了频繁的虚函数调用和解释执行的开销。
数据剪枝与跳跃索引
在查询执行阶段,ClickHouse会通过多种数据剪枝技术,减少需要读取和处理的数据量,从而显著提高查询速度:
跳跃索引(Skipping Indexes):ClickHouse支持多种跳跃索引类型,如最小最大索引(Min-Max Index)、集合索引(Set Index)和布隆过滤器索引(Bloom Filter Index)。这些索引在数据过滤时能够跳过大部分不相关的数据块,减少扫描量。
列过滤顺序:ClickHouse在执行查询时,首先评估选择性较高的列条件,以尽早排除大部分不相关的数据。这种优化策略能够在复杂查询中显著降低I/O负载和计算压力。
哈希表选择与优化
哈希表是ClickHouse在执行聚合和连接操作时的关键数据结构,选择合适的哈希表类型对性能至关重要:
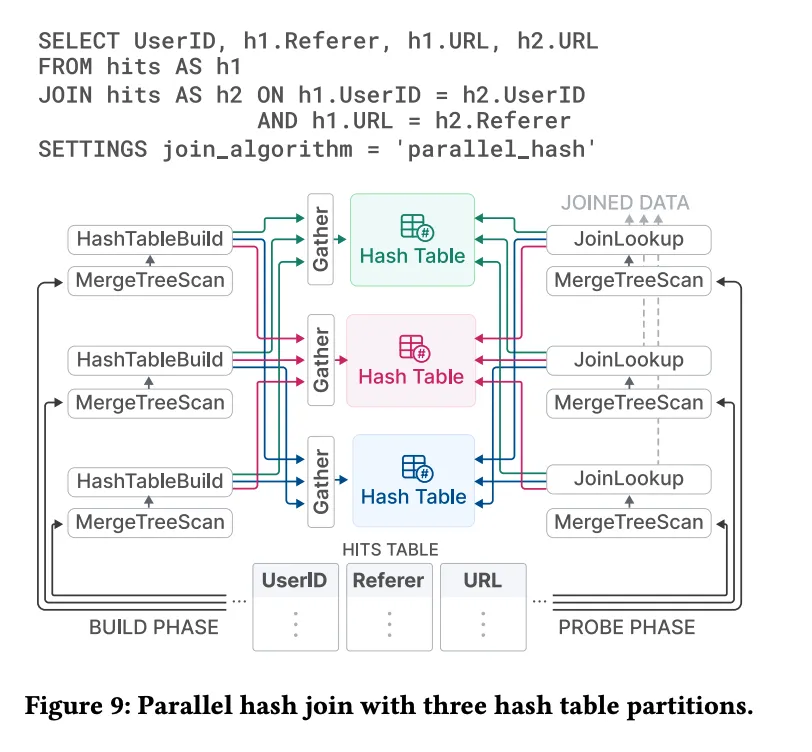
上图展示了哈希连接(JOIN)上CK做的优化,在构建阶段被分为多个并行规则的lane,每个lane负责不同的数据范围,每个数据范围根据哈希值,分配到不同的哈希表分区;而在probe phase,即探测阶段使用与构建阶段同样的分区策略,在并行线程间同步访问哈希表分区;且通过Gather exchange操作符,确保不通工作通道间数据访问同步,这种实现减少了构建阶段的锁争用,在多线程多核环境下,提高了连接(JOIN)操作的效率。
多级哈希表:对于大规模的数据集,ClickHouse会使用多级哈希表布局,将哈希表拆分为多个子表(例如256个子表),以支持海量键集。
字符串优化哈希表:针对字符串类型的键值,ClickHouse提供了特定的哈希表实现,能够根据字符串长度动态调整哈希函数,从而提升哈希表的查找效率。
哈希表清理与重用:ClickHouse能够快速清理哈希表以供后续查询重用,这通过版本计数器的方式实现,避免了不必要的内存释放与重新分配。
并行执行与任务调度
ClickHouse在并行执行查询时,采用了灵活的任务调度机制,确保在高负载情况下,各查询任务能够有效利用系统资源:
动态任务分配:在查询执行过程中,ClickHouse会根据实时情况动态分配计算任务,确保每个CPU核心都得到充分利用。此外,当某个查询线程完成任务后,它可以”窃取”其他线程的未完成任务,以避免资源浪费。
非阻塞操作:ClickHouse支持异步执行模式,当某些查询操作需要等待外部数据(如从远程节点获取数据)时,任务会被放入异步队列,以避免阻塞其他任务的执行。
3. 工作负载隔离与资源管理
为了在多用户和多查询环境下提供稳定的性能,ClickHouse提供了全面的资源管理和工作负载隔离功能:
内存限制与超额使用:ClickHouse允许用户为特定的查询或用户设置内存限制,并提供内存超额使用选项(memory overcommit),即在系统内存允许的情况下,查询可以使用超出初始分配的内存。
I/O调度与优先级:ClickHouse通过I/O调度策略,控制查询对磁盘和网络I/O的使用,防止某些查询占用过多I/O资源,影响其他重要任务的执行。
通过查询优化与性能提升技术,ClickHouse能够在高并发、大规模数据环境中,始终保持优异的查询性能。这些优化措施不仅减少了查询执行时间,还降低了系统资源的占用,使得ClickHouse在各种数据分析场景中表现卓越。
性能评估
在性能评估部分,论文通过多种基准测试和实际应用场景,全面展示了ClickHouse的高性能特点。评估的重点在于其查询速度、系统吞吐量、数据导入时间以及存储效率,具体分析如下:
1. 基准测试
ClickBench
ClickBench是一个针对ClickHouse的典型基准测试,主要用于评估其在处理网页点击流数据和流量分析中的表现。测试包含43个查询,模拟了实际业务中的多种分析场景,如广告点击分析、页面访问统计等。
数据集:测试使用了一个包含1亿条匿名页面点击记录的大表,这些数据源自全球最大的网站分析平台之一。
执行环境:所有测试在单节点AWS EC2实例上进行,该实例配备了16个虚拟CPU、32GB内存以及高I/O性能的磁盘。
在ClickBench测试中,ClickHouse展示了其极快的冷查询和热查询性能,冷查询指的是查询前清空了操作系统缓存,而热查询则是在有缓存的情况下进行的查询。
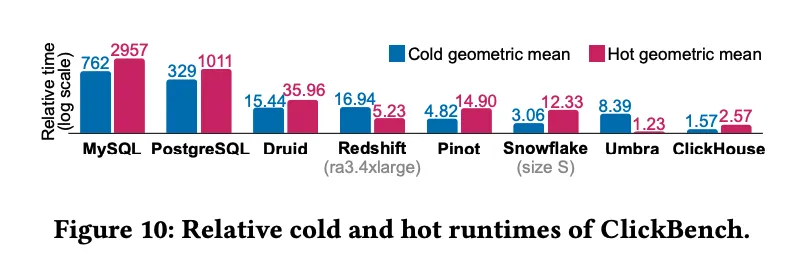
冷查询性能:ClickHouse在冷查询下表现出色,充分利用其优化的存储格式和数据剪枝技术,能够在短时间内返回结果。
热查询性能:ClickHouse在热查询时的表现更为卓越,利用内存缓存和已编译的查询计划,大幅减少了数据读取和计算时间。
如上图所示相比其他流行的分析型数据库,如Redshift和Snowflake,ClickHouse的冷查询和热查询性能均处于领先地位,尤其在处理大规模的聚合和过滤操作时优势明显。
VersionsBench
为了追踪ClickHouse在不同版本中的性能演变,ClickHouse团队还定期运行VersionsBench基准测试。这项测试结合了多个常见的查询场景,用以评估新版本的查询性能是否优于旧版本。
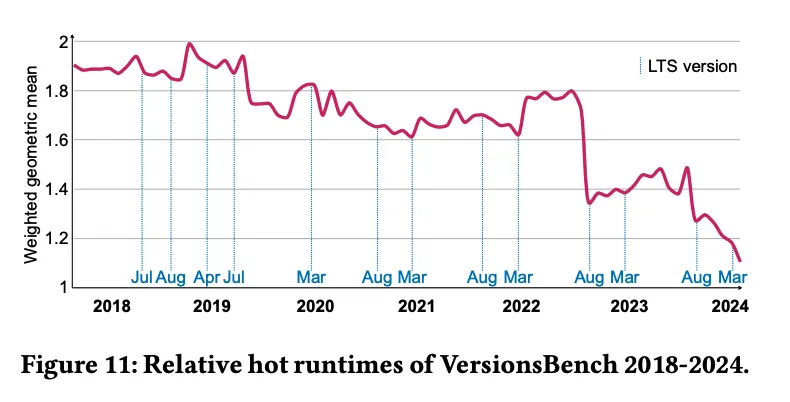
测试内容:VersionsBench包括ClickBench测试、MgBench、星型架构基准测试(Star Schema Benchmark),以及针对纽约市出租车数据的查询。
性能发展:从2018年到2024年,ClickHouse在每次发布的新版本中,查询性能平均提升了1.72倍。该性能提升主要得益于多次优化,包括列过滤顺序调整、查询优化器改进等。
TPC-H

ClickHouse还进行了经典的TPC-H基准测试,这是一个模拟决策支持系统的标准基准,主要用于评估数据库在复杂查询场景中的表现。ClickHouse的TPC-H测试使用了100GB规模的数据集。
查询优化与实现:在TPC-H的查询中,ClickHouse展示了其强大的聚合和连接处理能力,特别是在多表关联和大数据量聚合的场景中,表现尤为突出。
局限性:由于ClickHouse在2024年版本中尚未完全支持某些复杂的子查询和连接优化,因此部分TPC-H查询的性能不如其他数据库(如Snowflake)。不过,ClickHouse团队计划在后续版本中解决这些限制,进一步提升性能。
2. 实际应用性能
ClickHouse的性能优势不仅体现在基准测试中,还在实际的业务应用中得到了验证。例如,在大型互联网公司中,ClickHouse被广泛用于实时分析和监控系统,其高效的数据导入、低延迟的查询响应和强大的并发处理能力,使其成为处理海量日志和监控数据的理想选择。
3. 内置性能分析工具
为了帮助用户进一步优化查询,ClickHouse还提供了一系列内置的性能分析工具:
服务器和查询指标:ClickHouse能够提供详细的服务器级和查询级性能指标,如数据块读取量、索引使用情况等,帮助用户识别性能瓶颈。
采样分析器:用户可以通过采样分析器收集服务器线程的调用栈信息,进一步分析查询的性能。
Explain查询:用户可以使用
EXPLAIN关键字,查看查询的执行计划,了解优化器对查询的具体处理过程。
ClickHouse通过实际应用和基准测试,展示了其在大规模数据查询中的卓越性能。无论是在处理实时数据的场景,还是在面对复杂的查询需求,ClickHouse都能通过其高效的查询处理架构和优化技术,提供快速、稳定的查询响应。
总结与展望
ClickHouse在当前已经是流行的OLAP系统,凭借其高效的存储与查询架构,在处理大规模数据集的实时分析中表现已经很优异了。不过在未来,ClickHouse还是将继续优化事务支持、复杂查询处理和半结构化数据管理,以增强其在更多应用场景中的竞争力。

